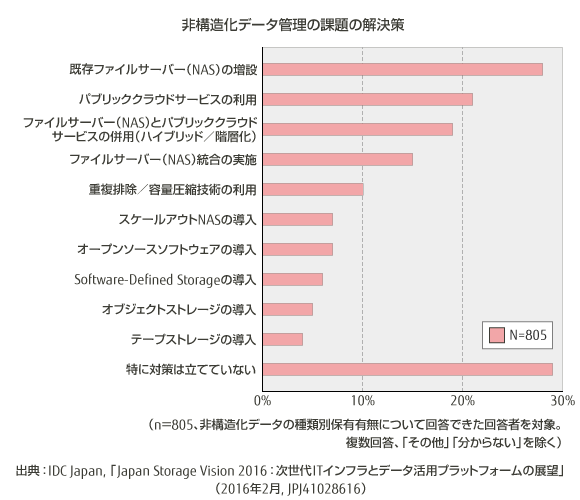
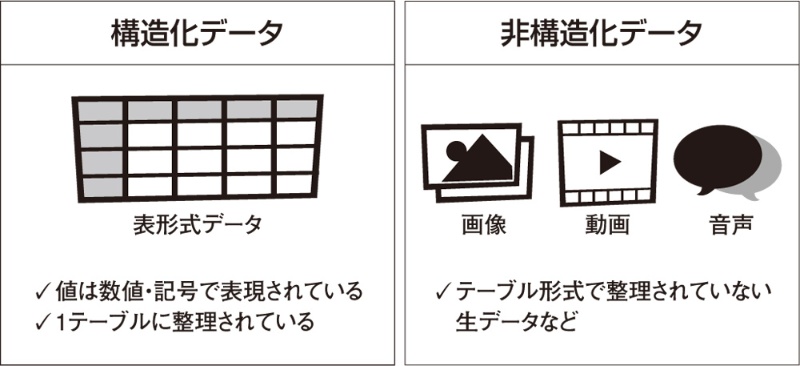
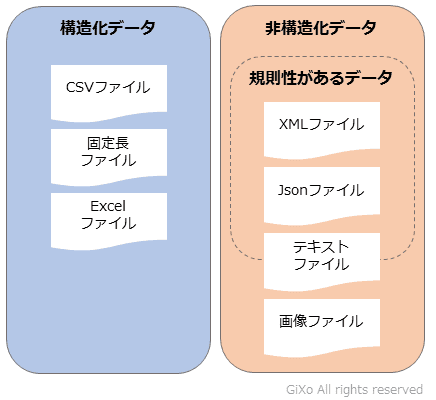
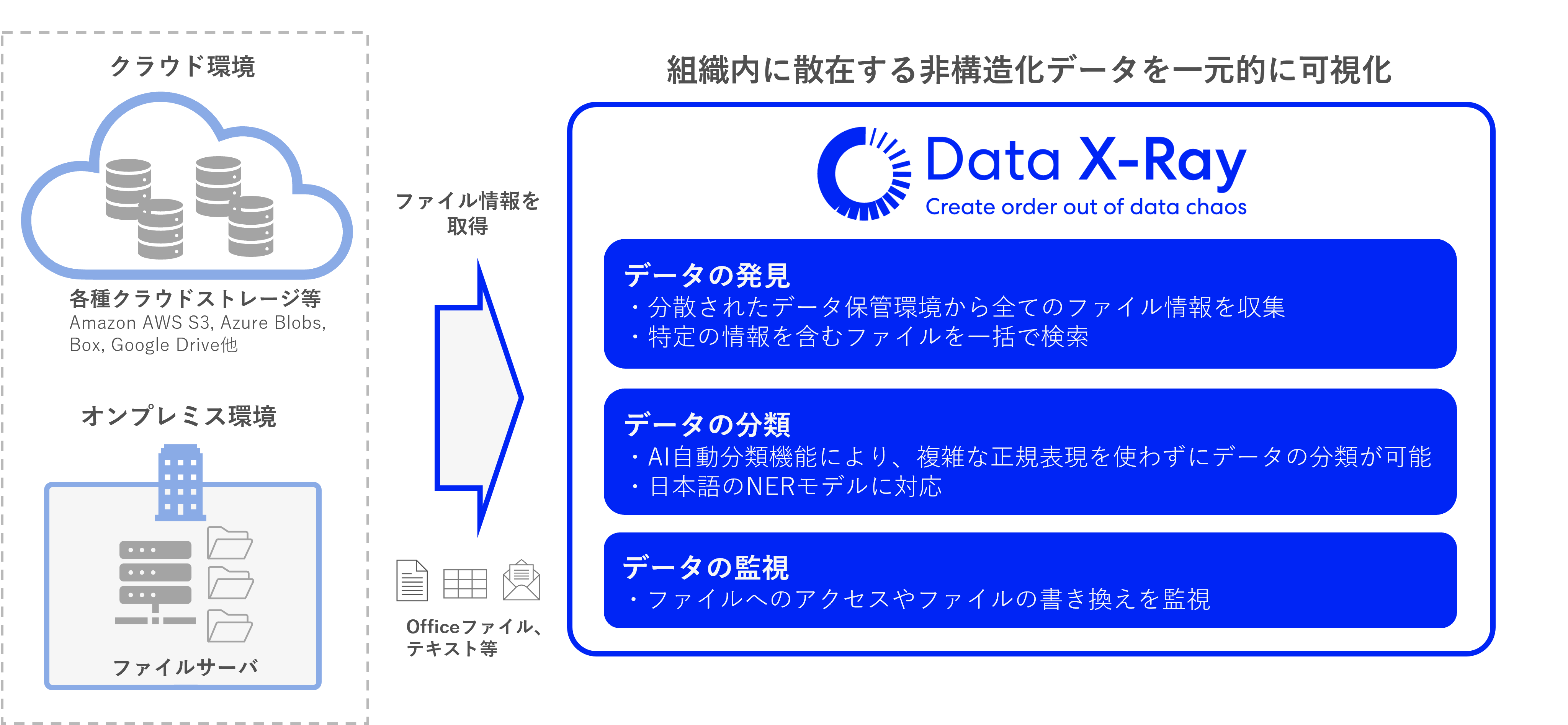
非構造化データ (ひこうぞうかデータ、Unstructured Data) とは、構造定義されておらず、主に関係モデルにうまく適合しないデータモデルに分類されるデータを指す。
データの変遷
従来より、人は商業活動や自然現象などを記録/測定した数値を、意味のあるデータ(情報)として活用してきた。そのような数値データを、より効率的に、より生産的に活用するために、計算機(コンピュータ)が生まれ、活用が高度化していく中で、主に関係モデルをベースとしたデータベースに構造化して格納されて活用したため、そのようなデータをのちに構造化データと呼ぶようになった。さらに、ITは、組織や人間の様々な活動をより効率的で生産的にするために、数値、文書、画像、音声、動画など、人のコミュニケーションをより表現するデータを活用するようになった。このようなデータは、構造化データという分類を超えて、完全な構造定義を持たない半構造化データ、あるいは、構造定義を持たない非構造化データとして分類されるようになった。
データベースの変遷
ITの進化にともなって、組織や人間の様々な活動から、数値、文書、画像、音声、動画がデータとして大量に生み出されるようになった。昨今では、それらを総称してビッグデータと呼ぶようになり、それらを格納して活用するためのデータベースも進化し、従来型データベースの問い合わせ言語がSQLであるのに対して、NoSQLと総称されるデータベースも登場するようになった。また、Hadoopなどの分散ファイルシステムも活用されるようになってきた。
- 関係データベース
- オブジェクトデータベース
- XMLデータベース
- 列指向データベース管理システム
- インメモリデータベース
- 分散ファイルシステム(Hadoopなど)
- 転置インデックス
- ドキュメント指向データベース
- NoSQL
非構造化データの取り扱い
各種インターネット検索エンジンの台頭がしのぎを削っていたころから様々なビジネスアプリケーションへの活用が本格化し、現在、一般的に知られる文書を構造化する方法としては、テキスト分析してメタデータをタグ付けしたり、画像、音声、動画からテキスト抽出して同じ方法を用いたり、特有のメタデータのタグ付けなどがある。このような非構造化データの取り扱いを実現する技術には、データマイニング、テキストマイニング、自然言語処理、機械学習、パターン認識、さらには人工知能の分野に含まれるものなどがあげられる。また、構造化データも含んで、非構造化データを処理する情報アクセス基盤(Information access infrastructure)としてエンタープライズサーチも活用されている。ビジネスアプリケーションのために非構造化データを分析して理解するソフトウェアは、SAS InstituteやIBM、SAP (企業)、HP オートノミー、オープンテキストなど様々な企業から提供されている。ソーシャルメディアの非構造化データの分析に焦点を当てたインターネットサービス企業も多数存在する。
関連項目
- UIMA
- データマイニング
- テキストマイニング
- 自然言語処理
- パターン認識
- ビッグデータ
- ワールド・ビーム
- ビジネスインテリジェンス
- ビジネスアナリティクス
- 機械学習
- 情報検索
- エンタープライズサーチ
脚注・出典
外部リンク
- ビッグデータプロジェクトの成功にはHadoopだけでは不十分
- 非構造化データのリスク管理 ~ビジネス・データの8割は非構造化データ